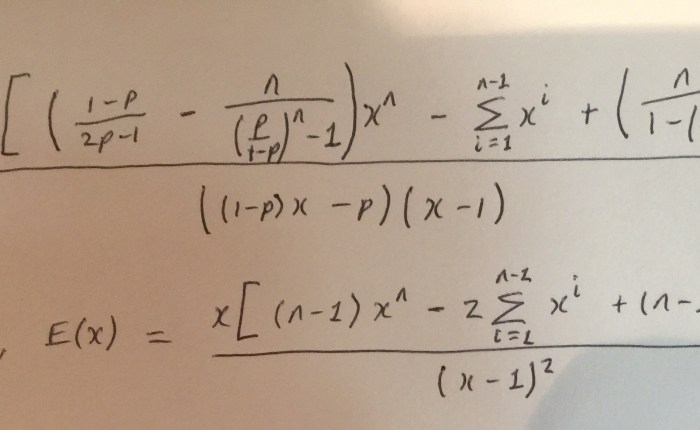
So, I promise this blog isn’t going to only feature puzzles and Excel challenges (next ‘real’ post on Friday, if all goes according to plan), but I enjoyed this week’s Riddler enough that I thought I should write something on it.
Consider a hot new bar game. … A marker is placed at zero on [a] number line. Then [a] coin is repeatedly flipped. Every time the coin lands heads, the marker is moved one integer in a positive direction. Every time the coin lands tails, the marker moves one integer in a negative direction. You win if the coin reaches -X first, while your friend wins if the coin reaches +Y first. (Winner keeps the coin.)
How long can you expect to sit, flipping a coin, at the bar?
Here are a few ways you can tackle it (if you’re just an Excel nerd and not a general nerd, you can skip to the last one…):
Continue reading “Bar games, advanced maths, and more circular references”