A few weeks back, I published an Excel challenge to score, and maybe solve, the game Mastermind in a spreadsheet. Today, I’m going to share some solutions to that challenge. To avoid repeating myself a lot, I’ll assume you’ve read the original challenge already – if you haven’t, I’d suggest you take a look at that first.
[The picture is my own Mastermind board, a particularly excellent gift from my sister-in-law which inspired this challenge.]
The spreadsheet with my solutions is here: Mastermind solution-Final
I haven’t annotated it much, since the solution is described below. For all the formulas here, I’ll use the cell references from this sheet, which has the code in cells C3:F3, and the first guess in cells C4:F4.
One last thing before I dive into the answers: only 2 people sent me their attempted solutions to this problem. I know a lot of people looked at it, but I don’t know whether the low response rate means that people (i) didn’t find it interesting, (ii) found it too hard or too easy, (iii) were interested but didn’t have time, or (iv) solved it but didn’t send me a solution. If you looked at it but didn’t send a solution, I’d appreciate it if you could let me know what bucket you fall in (either in the comments below or by email to theexcelements at <the domain name of Google’s popular free email service>.com). Obviously, I don’t think that you ‘owe’ me a solution just because you read my blog, but the distribution of answers will probably affect whether I set more challenges like this, and possibly how hard I make them.
Part 1 asked you to find formulas to score a given guess against a given code. Each guess / code pair gets two scores, black and white, where the black is the number of exact matches (same color and position) and the white is the number of inexact matches (right color but wrong position).
The black score is fairly easy to work out: in cell I4, enter =C$3=C4 to check if the first entry in the code matches the first entry in the guess (the $ means you can copy the formula down), and copy across to L4 to check the other three. Then the black formula in G4 can be either =COUNTIF(I4:L4,TRUE) or =I4+J4+K4+L4 (the second takes advantage of the fact that Excel treats TRUE and FALSE like 0 and 1 if you ‘force’ it to).
To meet both of the extra challenges, you could combine these into one and enter
=(C$3=C4)+(D$3=D4)+(E$3=E4)+(F$3=F4)
in G4, which both avoids using any functions and any helper cells.
However, I think the best solution that I can think of is
=SUMPRODUCT(–($C4:$F4=$C$3:$F$3)),
because it has the advantage of being scalable – in other words, if you wanted to compare codes with 1,000+ entries, any of the other options would require 1,000+ helper cells, or a formula thousands of characters long, while this one would only need to change the two range references.
The white score is a bit trickier to work out. If you work through each element in the guess to find if there’s a corresponding one in a different place in the code, then you have to keep back-tracking to make sure the one you match to hasn’t already been used (e.g. if there’s a 1 in the guess, and a 1 in a different position in the code, that might not be worth a point if you already used the 1 in the code to match an earlier 1 in the guess).
It turns out, the easier way to think of it is not in terms of the different positions in the code, but in terms of the different possible entries. For example, the white score associated with all the 1s will be the number of whites not used in exact matches which can be matched up between the guess and the code. But the number that can be matched up is just the smaller of the number in the guess and the number in the code (e.g. two 6s in the code and three in the guess means you can only match two), and the total number used in exact matches is just the black score, so we get this neat formula (from Wolfram Mathworld):

where 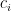


=SUM(IF(COUNTIF($C$3:$F$3,ROW($1:$6))>COUNTIF($C4:$F4,ROW($1:$6)),COUNTIF($C$3:$F$3,ROW($1:$6)),COUNTIF($C$3:$F$3,ROW($1:$6))))-G4
The blue COUNTIF gives
I don’t think anyone (other than me) attempted the extra-credit version of the white formula with no functions, so I won’t lay that out here – but it is possible!
Part 2 asked you to solve the game, and to do so in as few guesses as possible. There are lots of ways to approach this, and I won’t try to be comprehensive – but I will try to show how my solution was motivated.
First, it would certainly be helpful to know, after some set of guesses, how many codes are still possible, and which ones. The way I did this was to construct a table with a row for each code (1296 in total) and a column for each guess, with a score in each intersection. That way, after any guess, the table can be filtered on the corresponding column to show only the rows (codes) which match the score for that guess.
You can choose to construct your columns dynamically, so you only need 8 columns if you get there in 8 guesses, and so on, but I opted for a 1296 x 1296 table with all possible combinations, because it allows you to look a step ahead and think about what guess to make next based on the answers you’re likely to get (more on that in a moment). Once you have your scoring formula from part 1, you can use the Excel data table function to construct the full grid. Since it doesn’t change after it’s set up, I’ve hard-coded it to avoid slow recalculation.
Once you know what’s possible at any stage, you can start coming up with guesses. I did this by thinking in terms of the number of possible cases left: you start with 1,296 possibilities, and you need to get down to 1, so a good way to pick your next guess is by looking at how many different possibilities will be left for each score of that guess. Specifically, I looked at which guess would minimize the number of cases left in the worst case (e.g. if there are 45 possibilities with a score of BWW but only three with a score of BBB, I assume I’ll get BWW).
It turns out that this algorithm gets you to the answer very quickly; it never takes more than 4 guesses to work out the code, and a fifth to win the game. Although I came up with this independently, it turned out that Don Knuth, the godfather of modern computer science, described the same method in a short paper almost 40 years before me.
A few additional notes on this topic:
- Knuth’s paper also describes a number of other interesting properties of the algorithm – for example, it is only possible to win in 5 guesses with this method if you sometimes make a guess that can’t possibly be right (i.e. one that has already been ruled out as a correct solution).
- Dan Mayoh provided a nice alternate solution. His approach was to determine which possibilities were still left after each guess, then chose his next guess from among those possibilities. It performs a little worse in terms of number of guesses, but it’s much more compact because it doesn’t require the full 1296-column table.
- Koyama and Lai showed in a paper that the best possible algorithm for solving Mastermind requires an average of 4.30 guesses. My implementation requires an average of 4.47 [1].
A straight-up implementation of my solution is quite calculation intensive, and it required some optimization before I could run it on all 1,296 codes. You can check out the details in the spreadsheet, but the key speed-ups were:
- Hard-coding pieces that don’t change (i.e. the table of scores, and also the summary stats for each guess on the first turn).
- Creating a flag column to show which guesses are still possible after each round. This means that the COUNTIFS formulas for the later rounds only need to look at 2 columns (one covering all previous rounds, and one for the current round) rather than looking at one column for every guess so far.
- Sorting the table of scores by the score on the first guess (since the first guess doesn’t vary with the code) and using INDEX / MATCH to apply the COUNTIFS for later guesses only to the part of the range corresponding to the score on the first guess. You could also optimize further by sorting the section corresponding to each score according to the score on the next guess that would lead to, and then referencing an even smaller range with the formulas for later rounds.
Part 3 asked for a static solution, meaning a set of moves you can play every time, after which you’ll always be able to work out the code. I hadn’t attempted this at the time I posted, but I did come up with a solution later (but fair warning, it requires a little VBA!).
The first idea of the solution was to turn the 1296 x 1296 table I made in the last part into a pivot table. By adding some set of guesses as the column fields and getting a count, I can see how many possibilities will be left after each set of scores. A static solution requires getting all of these to be 1.
Second, there are way too many sets of guesses to try out every combination (even trying every set of 3 would require testing >200 million combinations), so we need some way of measuring progress after a partial set of guesses. I did this by looking at the average size [2] of the sets of possibilities for each set of scores. If a set of size N is split into subsets of size 

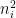
Now that we have a way of scoring a partial set, we can just start with an empty set and repeatedly add the guess that most reduces the score until we get to an average set size of 1, at which point we have a solution. This is where the VBA comes in: we set up the pivot table with the set of guesses so far, then use code to cycle through all the guesses not yet used, add them to the pivot table, see what the average set size is, and then remove them again. The guess that gives the lowest average set size is the one we use.
Below is the code that I used for running the pivot table for each new set of guesses. GuessRange is a named range containing the set of guesses to test, CodeCell is the cell containing the code (B3 in my file), and ScoreCell is a cell containing the average set size in the pivot (using SUMSQ), and after the algorithm runs the column next to GuessRange is populated with the average set sizes achieved by adding each extra guess. You can then pick out the best guess, add it in, remove it from GuessRange, and run again (you could write code to run the whole process including picking out and adding the best guess at each stage, but I prefer to keep my code light!).
For Each c In [GuessRange] ActiveSheet.PivotTables(1).PivotFields(c).Orientation = xlRowField c.Offset(0, 1).Value = [ScoreCell].Value ActiveSheet.PivotTables(1).PivotFields(c).Orientation = xlHidden Next c
If we follow this procedure, we get a static solution with 6 guesses. This is implemented in the second sheet in the Excel file, along with a lookup to figure out the answer based on the score of the 6 guesses. It’s easy to use Excel’s remove duplicates feature to confirm that every row of the table of scores for the six guesses is indeed unique.
I mentioned in my post that I wasn’t aware of this having been looked at before, but unfortunately I’m not as original as I thought – Dan Mayoh pointed me to the Wolfram Mathworld article, which notes that a static solution with six moves was found by Greenwell in 2000. It is not known whether it is possible to do it with fewer moves.
I hope you enjoyed the challenge. If you (would have) solved it a different way, please let me know in the comments.
[1] My original implementation actually took 4.7 guesses on average, but I picked up a small extra twist from Knuth that sped it up: if we have multiple guesses that would give the same maximum number of cases, we give preference to any which are still possible solutions (i.e. which are compatible with all the scores guesses so far). This increases the number of cases where we get a lucky hit and finish in 2 or 3 guesses. I implemented this in the spreadsheet by subtracting 0.001 from the ‘max number of cases’ score for any guess that was still a possible solution, which acts as a tiebreaker to put them ahead of multiple ones otherwise have the same score.
[2] Why not the worst case, as in part 2? It turns out that doesn’t capture enough information. If you optimize for the smallest size of the biggest set after each turn, you end up in a situation with lots of sets of size 2, not all of which can be distinguished by any one guess, which means that the next guess you add scores 2 no matter what guess it is, and you can’t use this to find the best guess. Using the average size instead effectively gives you credit for reducing the number of big sets, even if the maximum size stays the same. You can also come up with a different algorithm for part 2 by optimizing for the average set size instead of the maximum.
